I want to share some ideas I have to get feedback and potentially find some people to collaborate with. My understandings are constantly evolving, so all of this is very subject to change. I want to try to get down my current understanding and vision of the system I'd like to create. The project is exciting and a bit daunting, and I hope you will find the read worthwhile.
TL;DR: What if semantic graphs are the next evolutionary leap in human language and communication?
I believe that graphs represent a powerful paradigm which is not being utilized to its full potential -- especially in conjunction with schemas. I have difficulty articulating exactly why this is, and I hope that as time goes on it will become easier to do so. For now, let me just share the idea which has been spurring this endeavor.
Written language is a powerful medium for communicating ideas, the advent of which fundamentally changed many aspects of human life and civilization. Bear with me as I dissect some things that you and I might take for granted about written language. For many of us, written language has been a part of our everyday lives for as long as we can remember.
As a rule, much of the information contained in written language is encoded in the ordering and proximity of words within a sentence. Yes, some of the information is contained in the word itself (or rather in the dictionary definition of the word), but these atomic meanings of words can only do so much by themselves -- it's when we start combining the concepts that a new dimension of meaning is unlocked. Our nervous system is an incredible marvel which handles all of the complexity of language-wrangling without our even having to consciously think about it most of the time. It parses sentences and effortlessly provides us the underlying meaning based on the complex rules of grammar and language which we trained it on when we were young (or whenever we learned to read and write). But, just because we don't have to consciously think about it doesn't mean that there isn't an underlying, orderly system of rules which comprise the meanings. What if that orderly system of rules was made explicit?
Only relatively recently in the history of humankind have we had the tools which might allow such an undertaking. For a very long time, written language has served us incredibly well. Literature has a real and important impact on our lives -- it's been the primary medium for transmitting ideas for a very long time. Everything from the Declaration of Independence to the Lankavatara Sutra to The Lord of the Rings -- written language shapes the way we see and interact with the world. So why change it?
Note regarding the difficulty of conveying this idea:
A tool is only as useful as one's ability to use it. In this case, this means that the idea totally hinges on the user-interface (UI) of the graph. Since that UI currently doesn't exist, all of this explanation may well amount to a bunch of hand-waving. I hope to have that remedied as I build out these systems, but it is currently a recognized limitation. And, relatedly, since the UI implementation is still very much in the ideation phase, it can be difficult to realize/visualize the benefits which might be exposed in being able to interact with a graph-like abstraction of written communication.
It's a multi-step paradigm shift, so hang in there with me. First, let's consider an environment which could allow the explicit denotation of every semantic (meaning-bearing) connection in a given passage. Call it a graph. Let each word be a node, and every relationship (be it grammatical or implied) be a structured connection in that graph. The first impression may be: "Big deal, my brain already does that without me even having to think about it." It's true; we as humans don't need the semantic connections within a passage to be made explicit in order to understand the passage. (There is a jumping-off point here about benefits in a computer's understanding of language, but that can be explored another time.)
The next step in the paradigm shift is to consider multiple passages represented in this format. We can begin to get a glimpse of the power of such a system in this light. With current written language, we are very much limited by our brainspace for retaining the context of a passage (though we don't often think of it this way since there is no alternative). Have you ever been reading a passage only to run across some concept which was described earlier in the document, but which you have totally forgotten?
Imagine the graph for the document. First, at the sentence level, the explicit semantic connections would describe atomic assertions of meaning. Then at the paragraph level, different ideas may be referenced and expounded upon. Points may be reinforced. Now consider at the document level: differing perspectives may be explored in order to broaden the overall stance. Thesis points may be built up and supported by a foundation of related connections. All of these interactions are explicitly modeled in the graph.
So what? I believe the power of this paradigm lies in breaking the linear restriction of written text. One can (vaguely) imagine a future where a linear representation of text may not even be necessary to express or ingest assertions of meaning, but for now let's stick with the model of this semantic graph as built on top of an existing linear passage. One might imagine an interface which exposes the ability to follow the thread of a given theme or topic in a non-linear fashion through a document. The interface could guide you through the relevant places in the text which touch upon the specified topic, in addition to exposing related avenues of exploration via tangential semantic connections. One could imagine a reading application which, while displaying a familiar linear passage of text, exposes helpful visual cues derived from the underlying semantic graph. For example, perhaps by hovering over a concept, the view guides the user to the place in the document where it was defined. Or maybe a user could optionally enter a sentence-breakdown mode for complex sentences, where arrows and underlines help to delineate the flow of meaning through the sentence. Again, the UI portion of this is quite open for interpretation, and the possibilities are exciting.
Zooming out even further, what happens when you have multiple semantic documents interacting in this graph space? The medium enables the possibility of sharing context between environments. A concept or entity defined in a given context could be referenced by another graph. You start to get context-rich information by nature of its representation. How exactly this might look is very speculative and forward-looking. It would require a space for various contributors to operate on a shared graph, referencing common subgraphs/concepts with differing perspectives while maintaining overall integrity. To take some possible projected use-cases, consider:
Finally, zooming out to the full vision: I want to create a knowledge repository using this medium that allows all of the rich and varied perspectives of humanity to interact, and which represents the culmination of human civilization's understanding. I want it to have an immutable history which records the ways in which those perspectives and assertions interact. I want to give it as a gift to future generations, to let them learn from the way incongruous ideas and perspectives come to understandings, to allow them to avoid mistakes that we have made, and to let them learn from the past. Ultimately, I want it to promote peace and temperance, to reduce the suffering in the world.
There's a book that could be written about all of this, but suffice it to say that I believe that a well-engineered system could promote the convergence of perspectives in a way that does not lose nuance. I believe that giving a space for perspectives to interact which allows the varied perspectives to find common ground could promote empathy and kindness to overcome the animosity which can come with misunderstanding. There are many unsolved questions, and there certainly will be pitfalls to avoid and refactor around, but I believe it's possible (and probable) for such a system to drastically improve the quality of life on earth and reduce suffering wholesale.
Far out (☮) enough? Let's get into some of the implementation details.
My current understanding of the project is broken up into several pieces:
When combined together, the goal is to make a versatile semantic-graph editing ecosystem. The schema would provide a strictly typed environment for the graph to exist in. While the prior explanation of a graph-like abstraction over written language is one example of a schema environment, there could be many other valuable schema environments which emerge. A schemaful semantic graph is not much use without an intuitive way to interact with it, which is where the UI comes in.
Worth noting is that there are multiple facets to consider this system from. From one perspective will be the next proposed steps in implementing initial prototypes. Other perspectives will deal with anticipated issues that will need to be solved either to scale or to enable desired features, but will be (even more) conceptually loose and subject to change.
This project outline is quite high-level and could be broken down into more layers, but I hope that this representation aids in getting a general understanding of the pieces involved. For example, the "graph environment" will eventually need to encompass everything from distributed persistence and real-time collaboration to history tracking and conflict-resolution. It's also not incredibly clear from this view where the borders between the graph environment and the user interface are delineated. The user interface will need to maintain a copy of the graph in memory (or at least a copy of relevant parts of the graph) and keep them synced with some persisted store. I'll give an overview of each layer to better illuminate the proposed solution space.
The schema will serve as the backbone for a given environment. My vision is for all possible schemas to remain interoperable by exposing a root set of primitives which can be combined and built upon to build arbitrarily complex schemas. The current version of these primitives is as follows:
Notably, this list lacks an entry for "edges". This is because there will only be two kinds of primitive edges: standard and slot (though this is subject to change). Slot edges will be used to denote that a node is fulfilling a constraint/slot for a given template, and standard edges will be used for everything else.
It would be easy to get into the weeds about the implementation of these schema elements, particularly since I am in the weeds with them, attempting to nail it all down. This is what I'm currently working on implementing, with the goal of getting a prototype done to be able to integrate with a new UI prototype. Below, in the "Schema Elements" I will attempt to give a brief technical overview of the main schema elements. Feel free to skip it if the technical details are not interesting to you. And feel free to reach out for a more comprehensive explanation if they are especially interesting to you -- I could use the help!
Note on the difference between schema items, operative items, and instantiated items ("item" here refers to a node or a template). A "schema item" is assumed to be totally uninstantiated -- it represents a model for the item which, when instantiated, will have all of its constraints fulfilled and become a concrete instance. In other words, a schema item essentially just provides a list of constraints. An "instantiated item", on the other hand, carries concrete data and has no remaining constraints to fulfill -- it is ready to be used and referenced in an actual graph. An "operative item" is in a state between instantiated and uninstantiated, and will be discussed further below. Essentially this state indicates that when instantiated, certain constraints are already fulfilled with pre-defined values. This concept is helpful in templates.
Nodes are the fundamental building blocks of the schema. They can have zero or more labels and zero or more fields (name/data pairs) with explicitly defined types of data.
Labels are meant to serve essentially as contracts for constraints. A given node type can implement 0 or more Labels, and each label can impose 0 or more constraints (e.g. a label might require a certain data field to be present on the node). So when a node type is instantiated, all of the constraints from its labels must be fulfilled.
Templates represent descriptions of reusable subgraph structures. Templates will facilitate the creation of complex semantic meanings while keeping a well-defined and strongly-typed schema. A template may consist of a combination of instantiated nodes (see note about dictionary libraries below), operative nodes, instantiated templates, and operative templates. An operative node plays the role of a placeholder or "hole" in the template. Take for example a template called "PerformAction". PerformAction will have two operative nodes (or holes) -- one for the subject which is performing the action, and one for the action performed. In ascii, the template may look something like:
(Noun: Subject)-[standard_edge]->(PerformedAction)<-[standard_edge]-(Verb: Action)
The Subject and the Action are operative nodes. They have some constraints which must remain as stated: the Subject must have the "Noun" label, and the Action must have the "Verb" label. In addition, the Subject and Action must both be able to connect to the "PerformedAction" node. No node will be allowed to fill these slots which doesn't fill these constraints. It's useful to think of these operative nodes as being placeholders which describe some (more or less) restrictive shape which needs to be filled.
Operative templates are templates which are used within other templates but have not been fully instantiated. If a template has been fully instantiated when referenced in another template, then when a user instantiates the higher-level template they will not need to worry about fulfilling the constraints from that template. But if a template has not been fully instantiated when referenced within another template, the instantiator must fulfill all of the constraints for the top-level template as well as any constraints remaining from the lower-level templates. In theory, this allows template creators to optionally lock in particular constraints in lower-level templates to restrict the expressiveness of the new top-level template. For example, let's consider a(n admittedly contrived but hopefully conceptually helpful) meta-template "Pushed", which contains in it the previously discussed template "PerformedAction" and an implied template "ReceivedAction". For brevity, the inner templates will be collapsed in the ASCII graph to be edge-like.
(Noun: Subject)-[PerformedAction]->(Verb: "Pushed")<-[ReceivedAction]-(Noun: Object)
In the previous definition of "PerformedAction", the Action slot was an operative node. However, in this meta-template, that Action slot is no longer operative and has been filled in with the concrete node of "Pushed". In this meta-template, the only operative nodes are for the Subject and the Object.
Implied in this system but not explicitly mentioned yet is the need for a library graph which would accompany each schema. Any instantiated node which is referenced within a template (such as the "Pushed" node in the previous meta-template) should be an actual concrete instance of a node with a single unique ID. This would allow graph environments which use this schema to instantiate these templates without creating a copy of that node -- instead the instantiated template would just reference the already-instantiated library node. The exact details of how this will work are still a bit unclear -- for example it seems like it would be useful to allow users to instantiate instances of templates and nodes without explicitly needing them to be referenced in a higher meta-template. One extreme case which would push for innovation in this area would be in an imagined "English Language" schema, where each word could be instantiated in the library graph as a template which contains a textual dictionary definition of the word and a subgraph semantic representation using other word templates. This could present problems in shipping that entire large dictionary graph to every client operating within this schema environment, and it might call for some kind of hosted dictionary graph for that schema, which clients could pull definitions from as necessary. Again, quite speculative and probably not the most pressing concern, but something to think about for the future.
Schemas should be able to be composed and extended. Ideally in the long term, this would take place with some kind of dependency-management system, which would simplify many aspects of working with schemas, for example the dictionary/library concept. However, a dependency-management system is a complex undertaking, and one that is not necessarily the highest priority at this stage while the value of the system as a whole is unproven.
I anticipate having a Rust interface for building, manipulating, and extending schemas, but see a case for exporting schema artifacts as JSON or some other agnostic language.
This right now is the most speculative layer, and could take many forms depending on the use case. The main takeaway here is that there needs to be some persisted data store which holds the actual graph which is created with respect to a given schema.
For initial implementations, this layer could likely be a simple database meant to facilitate a single user interacting with a persisted graph of their document. Longer-term, it seems like collaborative editing (perhaps using CRDTs (Conflict-Free Replicated Data Types)?) and shared graph environments would become warranted. And longest-term, a complex distributed system would probably need to arise, exposing capabilities for conflict-resolution, branching structures, and history tracking. I think of this layer as git-like, after a fashion.
An open question with these multi-user graphs is that of differing schemas. You could imagine an environment in which different communities used different domain-specific schemas, but still wanted to interact at some level. This is where a schema dependency system could come in handy -- domain-specific schemas could interact with other domain-specific schemas at the level of the greatest-common-denominator of their shared schemas (e.g. maybe at some standard library "English language" schema).
I'm far from a blockchain expert, but I could also see this space eventually making use of the distributed, trustless validation provided by blockchain to ensure data integrity and provide a transparent history for transparency-critical graphs.
This is an exciting arena, in which it is difficult to imagine all of the possible UI implementations which could eventually arise to interact with these semantic graphs. There are several layers at play even in the User Interface, an I'll try to explain them in a modular way so as to illustrate that the possible implementations really are wide and varied.
My initial approach is to use Reactive Signals (via Leptos) to create an in-memory graph capable of driving the user interface. What kind of user interface this reactive graph is driving will depend on the desired application. For example, I've experimented with using the semantic reactive graph to power application-routing, where the underlying graph is interacted with via the URL. For now I'll focus on the UI for editing a written-language-like graph medium as described previously.
I think that a good starting point for the UI of this graph language is very similar to a Rich-Text Editor (RTE). I've taken a lot of inspiration from the Prosemirror project. I envision an RTE-like experience which gives the ease of use and familiarity of a text editor, while actually building a graph under the hood while the user is typing and interacting. Each word would be a node.
The editor would need to support the manual creation of the semantic constructs between words and higher-level concepts, but I anticipate in the long-run that AI models would do the heavy lifting of generating semantic structures from textual inputs.
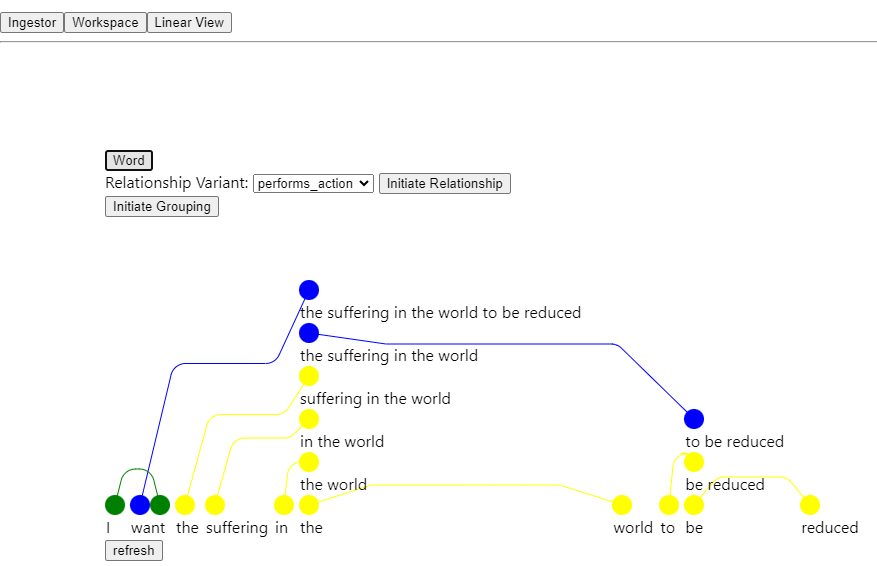
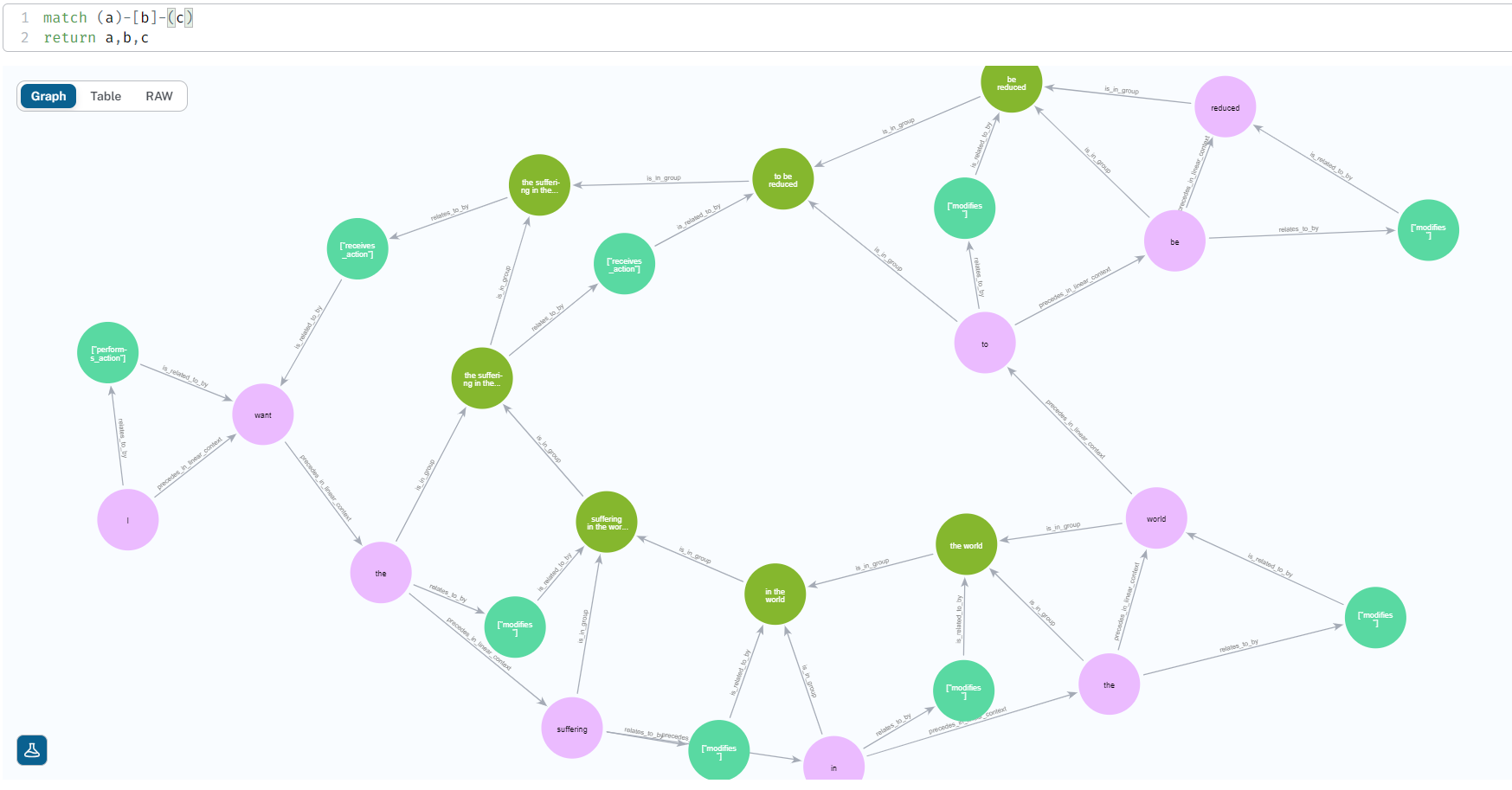
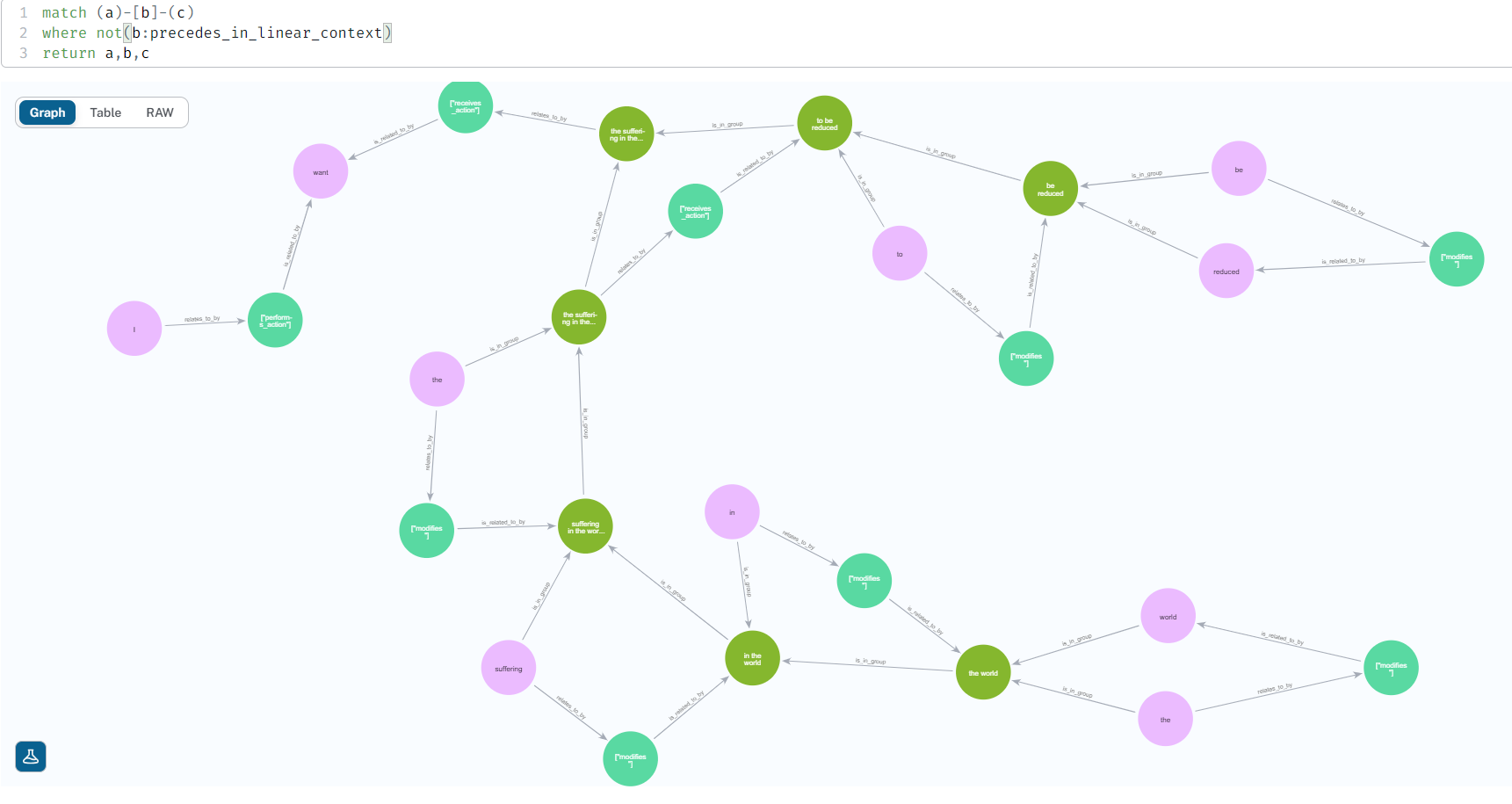
Here is an early prototype demonstrating the concept. This prototype doesn't allow Rich-Text Editing, but does allow the manual creation of semantic edges between word nodes. Note that it doesn't implement the schema system described earlier in the document, but is rather just a proof of concept and playground for creating semantic graphs from text. The first image is of the UI, and the second is of the graph created in a Neo4j database which reflects the UI state. The third is a less-cluttered graph representation by excluding the "precedes_in_linear_context" edges.
That prototype was made in Javascript, and since then I've been learning Rust and re-building the user interface as a true RTE. While I have an initial implementation somewhat fleshed out, I'd really like to build the schema system and make sure they can interoperate -- so work on the schema system is priority right now for me.
My vision for the project is very optimistic and ambitious. I find the prospect exciting. However, I'm a mediocre programmer with glaring holes in my understanding of many of the fields which will ultimately be required to realize anything close to what I have in mind. It seems like the only real hope is to crowdsource the effort and build something beautiful and transformative together. I welcome any help or input on the project, though I'm still trying to figure out a way to channel possible future contributions since so much of the architecture and concepts at play are in flux. I absolutely intend for the project to be entirely open-source, it's just a matter of getting some code to a point where it's worth sharing -- but when that happens, Github will probably be the place where this initiative lives.
The eventual goal of the language would be to essentially be a superset of written language. Any meaning captured in the graph format should be translatable back into written language (though the reverse might not hold true). The translation back into written language might be very verbose or unwieldy (e.g. The dog's state on Dec. 6th was brown. The dog's state on Dec. 6th was fluffy. The dog's state on Dec 6th was...), but the backward compatibility should be maintained.
I believe that a project like this is important to keep free from the influences of profit. A future where the very medium used to communicate is monetized is not a future that I want to contribute to. I believe it's important to maintain the vision and objective of reducing suffering and enabling access to knowledge for everyone, regardless of socioeconomic status. There's a lot more I could say on this topic. I am dedicated to keeping the project a non-profit endeavor to improve the quality of life on earth generally. It is important to be free from any pressure to monetize, as this would run counter to the goals of the project.
In addition, I anticipate difficult questions regarding content moderation and viewpoint suppression. I don't claim to know the best answers of how to handle these situations right now, but it's clear to me that there needs to be a transparent system of power and influence with regards to decision making in this arena. These kinds of decisions cannot be made to placate some panel of advertisers worried about their wallets. They need to be made in the open, and by taking into account diverse viewpoints. What exactly a governing structure might look like is an open question, but whether it should be free from external, self-serving influence is not. Of course, all of this is assuming the first steps of the project are successful and useful, which is far from apparent at this point.
Thanks for reading! I hope if nothing else that this post served to stir up some thoughts about the future of communication and the potential benefits for humanity that a graph-based communication system might provide. If you are interested in collaborating, please reach out. Feel free to create an issue in the Codeberg repository for this blog, I'd love to hear from you.